

Dokumente zum Herunterladen

Für die meisten Familienforscher, die wie ich weder im Lesen von Dokumenten in handschriftlicher Kurrentschrift (die manchmal den Eindruck erwecken, als sei ein Huhn über das Papier gelaufen) besonders geübt sind, noch in der Schule ein Latinum erworben haben, ist es eine fast unmögliche Aufgabe, derartige Dokumente auszuwerten. Leider haben sich die Pfarrer und später die Standesbeamten selten um eine lesbare Darstellung ihrer Beurkundungen bemüht. Selbst nach Einführung der Sütterlin-Schrift ist die Auswertung der Dokumente daher eine zeitaufwendige und mit viel „Raten” verbundene Aufgabe geblieben. Da „professionelle” Hilfe in der Regel teuer ist, haben sich viele Familienforscher – so auch ich – auf die Verwendung von Sekundärquellen beschränkt (mit allen damit verbundenen Problemen hinsichtlich der Richtigkeit und somit der Glaubwürdigkeit), obwohl einige Archivare und sogenannte „ernsthafte” Familienforscher dieses Vorgehen zum Anlass genommen haben, eine „Mehr-Klassengesellschaft” in der Genealogie einzuführen, indem sie die Hobby-Genealogen als „Datensammler” diskreditierten. In solchen Fällen war mein einziger Kommentar: „Was schadet es der deutschen Eiche, wenn die Sau sich daran schabt?”😉
Umso erfreulicher ist daher eine Neuerung, die von der Plattform MyHeritage eingeführt wurde. Seit einigen Tagen kann mit dem Werkzeug „Scribe AI” jeder angemeldete Nutzer historische Aufzeichnungen wie Briefe oder Urkunden transkribieren und analysieren. Nach nur wenigen Minuten erhält er „detaillierte KI-Erkenntnisse” aus diesem Dokument.
Da ich als ehemaliger IT-Mitarbeiter bei derartigen Versprechungen sehr skeptisch, aber auch neugierig bin, habe ich das Werkzeug mit den ersten 100 Urkunden getestet, die ich trotz meiner Auswerteprobleme gesammelt habe – und bin mehr als nur angenehm überrascht.
Mit diesem Werkzeug stellt MyHeritage ein erstes KI-Tool zur Verfügung, das auch „Hobby-Familienforscher” in die Lage versetzt, aus unleserlichen historischen Dokumenten Erkenntnisse und Daten zu gewinnen.
Die Ergebnisse meines Tests habe ich hier "Dokumente herunter laden" zum Download bereit gestellt, so das jeder Interessierte sich von den Ergebnissen der KI-gestützten Auswertung ein eigenes Bild machen kann.

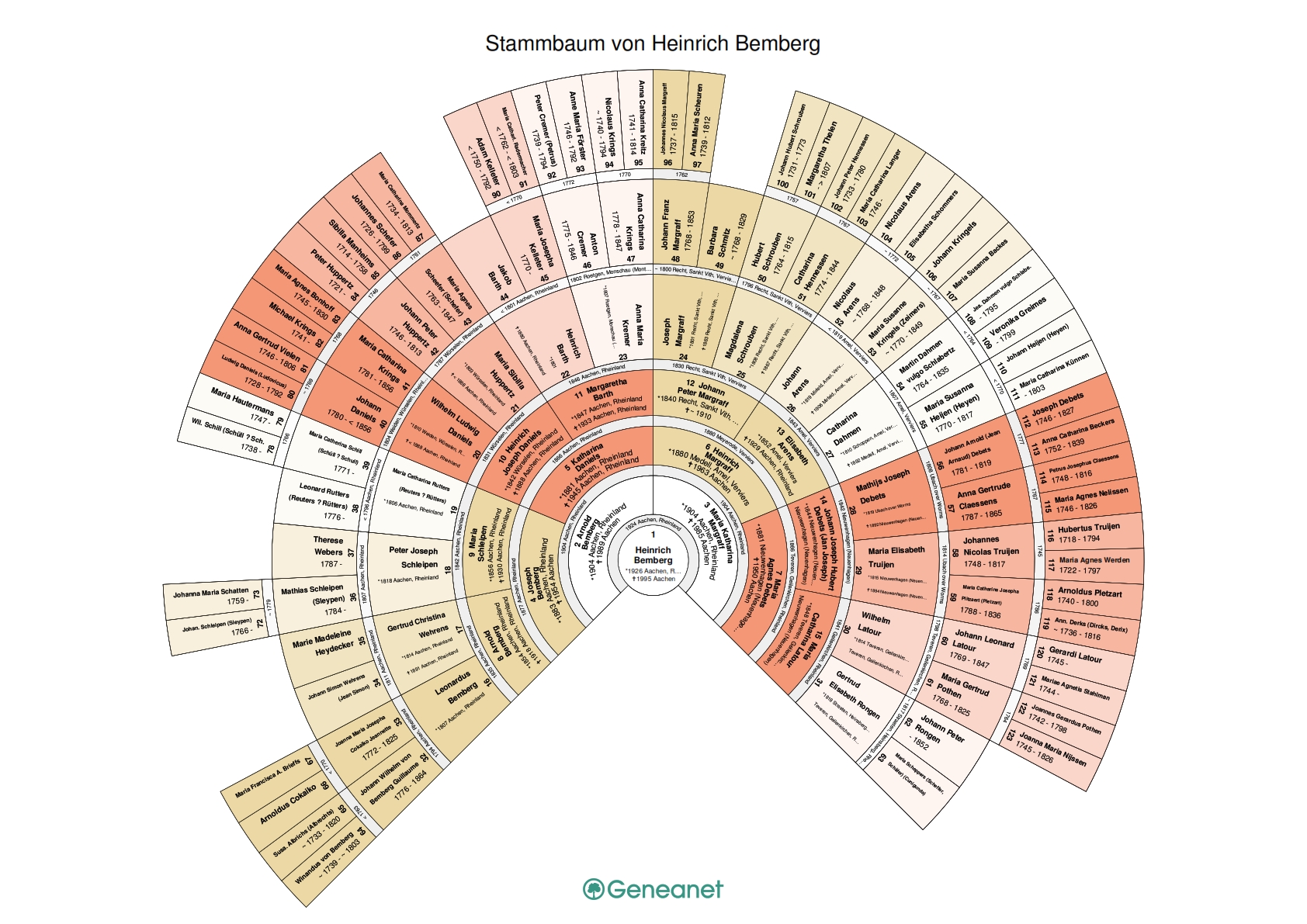
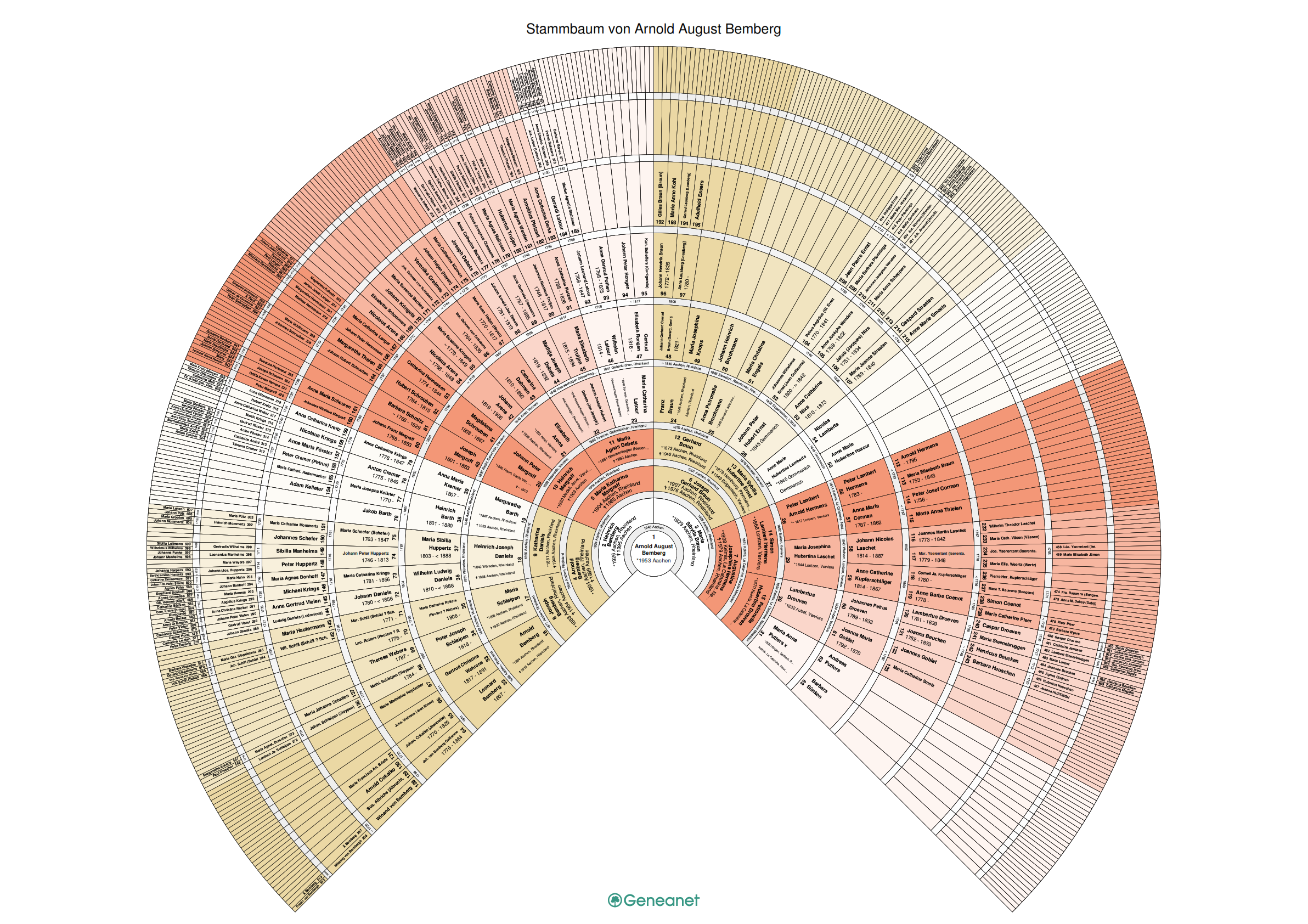
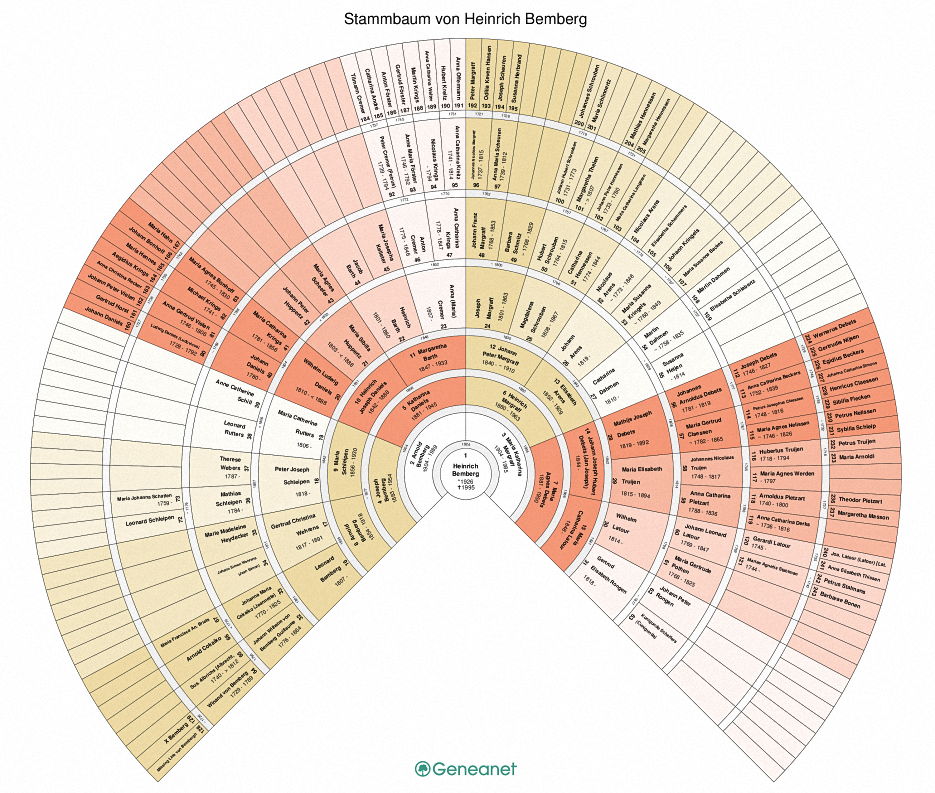


 Die neue Version der Genealogie der Familie Bemberg vom Bemberghof ist fertiggestellt und online.
Die neue Version der Genealogie der Familie Bemberg vom Bemberghof ist fertiggestellt und online. 